
|
|---|
脱試行錯誤!フィードバック制御の最適化は体系的アプローチで
ラズパイとPythonで一緒に!センサ・フュージョン入門
フィードバック制御調整時のトレードオフ
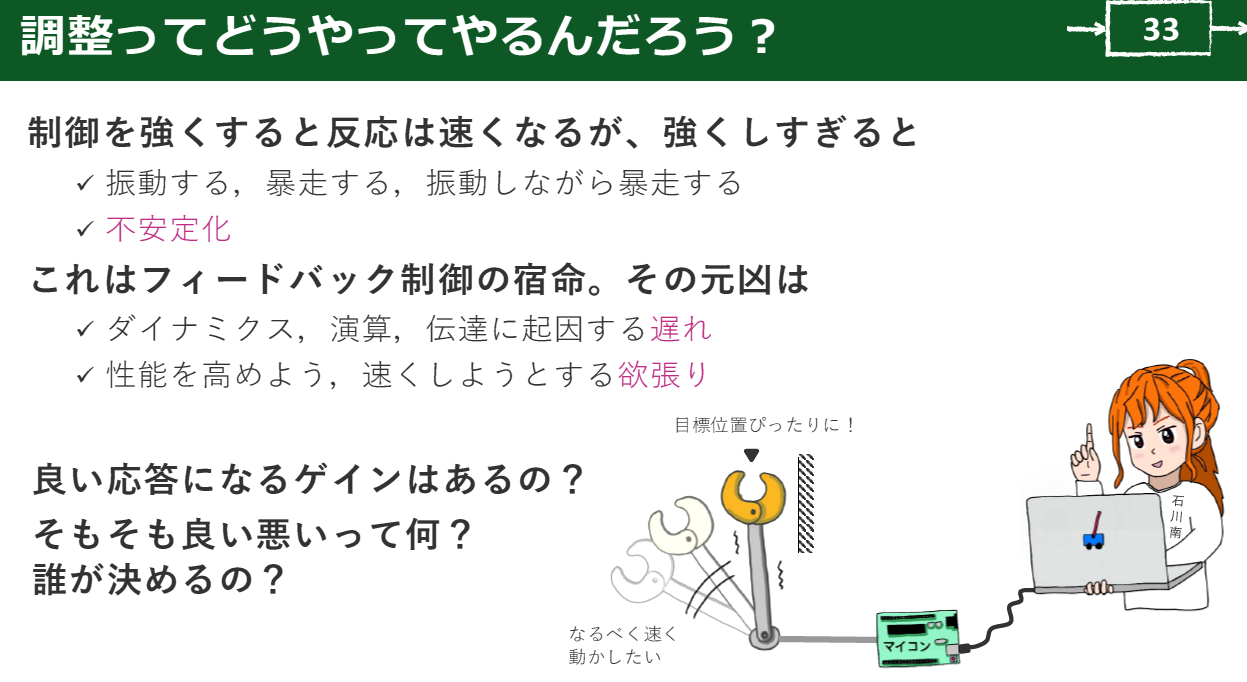
|
|---|
| 図1 フィードバック制御では,ゲイン$K$を大きくすると応答は速くなるが,振動や行き過ぎが現れる.速さと振動は同時によくならない関係にある.画像クリックで動画を見る.または記事を読む.詳細はVOD/Pi KIT/data]ラズパイとPythonで一緒に!カルマン・フィルタ&センサ・フュージョン入門 |
フィードバック制御では,ゲイン$K$を変えると応答のふるまいが変わります.$K$が小さいと応答は穏やかで,目標へ到達するまでに時間がかかります.$K$を大きくすると応答は速くなりますが,振動や行き過ぎが現れやすくなります.速さと振動は同時によくならない関係にあり,この関係がトレードオフです.
このトレードオフは,対象がもつダイナミクスや遅れに由来します.実際の装置には慣性や摩擦があり,操作を加えても状態は即座に変わりません.制御器は,こうした性質を前提に設計する必要があります.単に応答を速くしようとすると,振動や不安定さが表に出ます.
- ゲインが小さいと応答は遅い
- ゲインが大きいと応答は速いが振動しやすい
- 速さと振動はトレードオフの関係です
試行錯誤に頼らないための考え方
制御の調整を試行錯誤だけで進めると,設計者の感覚に強く依存します.ある人にとってよい応答でも,別の人には不十分に見える場合があります.この違いは主観の差です.工学では,主観だけに頼る設計は説明が難しくなります.
この問題を避けるために,モデルを使った体系的な設計を行います.モデルは,対象のふるまいを簡略化して表現したものです.モデルがあれば,ゲインを変えたときに応答がどう変わるかを事前に考察できます.調整の理由を言葉として説明できる点が重要です.
- 試行錯誤は設計者の主観に依存しやすい
- モデルはふるまいを共通の言葉で表す道具です
- 調整の根拠を説明しやすくなります
制御設計には設計者の視点が含まれます
制御の定義には,注目する対象,注目する状態,目標とする状態,操作が含まれます.ここで重要なのは,何を状態として注目するか,どの値を目標とするかを決める主体が設計者である点です.工学の制御は,自然現象を記述する理学とは異なり,設計者の意図が必ず入ります.
この意図を曖昧なまま調整すると,設計結果の評価が人によって変わります.体系的なアプローチでは,目標と評価基準を明確にし,モデルを通じて調整を行います.この流れによって,設計者が変わっても理解できる制御設計が可能です.
- 制御設計には設計者の意図が含まれます
- 評価基準を明確にすると議論が共有できます
- モデルは意図を形にする役割をもちます
ラズパイとPythonでの体系的アプローチ
ラズパイとPythonの環境では,対象の挙動を観測し,モデル化し,制御器を設計する一連の流れを小規模に試せます.センサから得たデータを使って状態を把握し,制御の結果を可視化できます.この過程を通じて,試行錯誤から一歩進んだ設計の考え方を身につけられます.フィードバック制御を体系的に理解することが,安定で再現性の高い制御につながります.
〈ZEPマガジン〉参考文献
- [VOD/Pi KIT]MATLAB/Simulink×ラズパイで学ぶロボット制御入門,ZEPエンジニアリング株式会社.
- [VOD/KIT]MATLAB/Simulink×ラズパイで学ぶロボット制御入門,ZEPエンジニアリング株式会社.
- [VOD/Pi400 KIT]SLAMロボット&ラズパイ付き!ROSプログラミング超入門,ZEPエンジニアリング株式会社.
- [VOD/KIT]確率・統計処理&真値推定!自動運転時代のカルマン・フィルタ入門,ZEPエンジニアリング株式会社.